High-Performance Data Management
HariKube delivers exceptional performance through data distribution and optimized database routing. By offloading resource-intensive workloads from ETCD, it ensures consistent responsiveness and operational efficiency at scale.
TL;DR
Applications can quickly retrieve and store data-even when the data is spread across multiple databases-thanks to optimized routing. Compared to a single overloaded database, this distributed approach reduces contention, balances load, and delivers faster, more reliable responses under scale.
HariKube efficiently distributes workload-intensive operations across multiple databases, minimizing bottlenecks and ensuring consistent performance even under heavy traffic. Under high load, a single service’s database remains isolated, ensuring that performance issues don’t impact data access for other services or workloads.
HariKube routes each resource type to the most suitable database based on its access pattern and scale needs. It supports multiple databases simultaneously, enabling diverse workloads to run in parallel without contention or performance trade-offs.
HariKube offloads microservice and high-volume data from ETCD to external databases, preserving ETCD’s speed and reliability for core Kubernetes operations. By distributing data across purpose-built storage backends, it minimizes contention and reduces the operational burden on ETCD even in large-scale environments.
Kubernetes has become the de facto standard for orchestrating containerized applications due to its flexibility, extensibility, and ability to automate deployment, scaling, and operations. It enables teams to adopt microservices architectures, build scalable cloud-native platforms, and maintain service reliability even under dynamic workloads.
At the heart of Kubernetes lies ETCD, a distributed key-value store that serves as the central source of truth for the cluster. All critical cluster data-such as node states, configurations, secrets, and custom resource definitions (CRDs)-are stored and retrieved from ETCD. While ETCD is fast and reliable for core Kubernetes operations, it’s not designed to act as a general-purpose data store.
As teams scale their Kubernetes environments or begin to use CRDs for large, dynamic workloads, ETCD becomes a performance bottleneck:
ETCD under Kubernetes cannot scale horizontally – Every ETCD replica stores the full dataset and participates in quorum-based consensus, making it difficult to scale with increasing data volume or high-throughput workloads. Adding more replicas increases fault tolerance, not capacity.
Limited capacity even with vertical scaling – ETCD struggles to handle large volumes of high-throughput data, even when deployed on high-performance hardware. Its single read/write path and centralized data access model create a bottleneck under heavy load, limiting overall system scalability.
Using ETCD to store non-core, high-volume workloads – such as application state, dynamic configuration, or large custom resource datasets-can overwhelm its intended capacity. This not only slows down critical control plane operations like scheduling and service discovery but also increases the risk of cascading failures across the cluster when ETCD becomes unresponsive or resource-constrained.
Complex and risky maintenance and recovery – As ETCD usage expands beyond core Kubernetes data, backup and disaster recovery processes become more error-prone and time-consuming. Since ETCD remains a single point of failure for the control plane, any misstep in handling its growing data volume can lead to critical cluster and business service outages.
In-memory storage and API-level filtering limit scalability – Kubernetes stores all data in memory and performs filtering at the API server level, which becomes inefficient and resource-intensive for services managing large datasets. HariKube solves this by offloading data to relational databases, enabling efficient querying and filtering directly at the storage layer.
This is where HariKube introduces a transformative solution. Why HariKube?
HariKube implements a multi-database architecture that offloads non-critical and workload-intensive data from ETCD to purpose-optimized databases such as MySQL and PostgreSQL. It sits between the Kubernetes API server and database backends via the middleware layer that routes data based on resource type, namespace, or other characteristics.
Creating 160,000 records across 320 threads
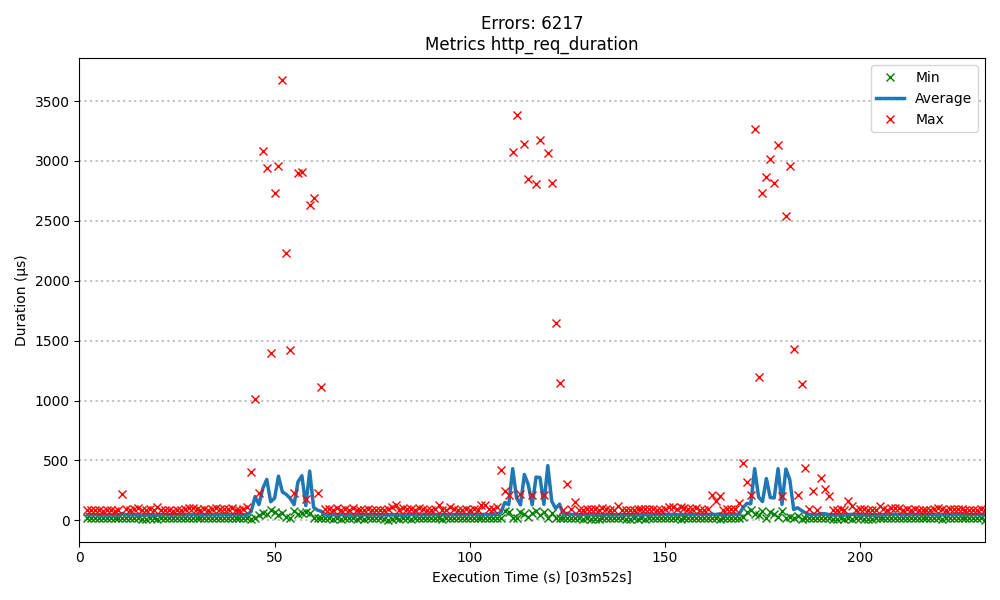
While HariKube's performance is crucial, maintaining a low overall error rate is equally important to ensure reliability and user trust. The next bechmark shows that the single database setup had 6,210 errors out of 160,000 requests (~3.9% error rate), compared to 0 errors generated by HariKube.
Total execution time: 3m52s
- Errors: 6217
- Total execution time: 3m52s
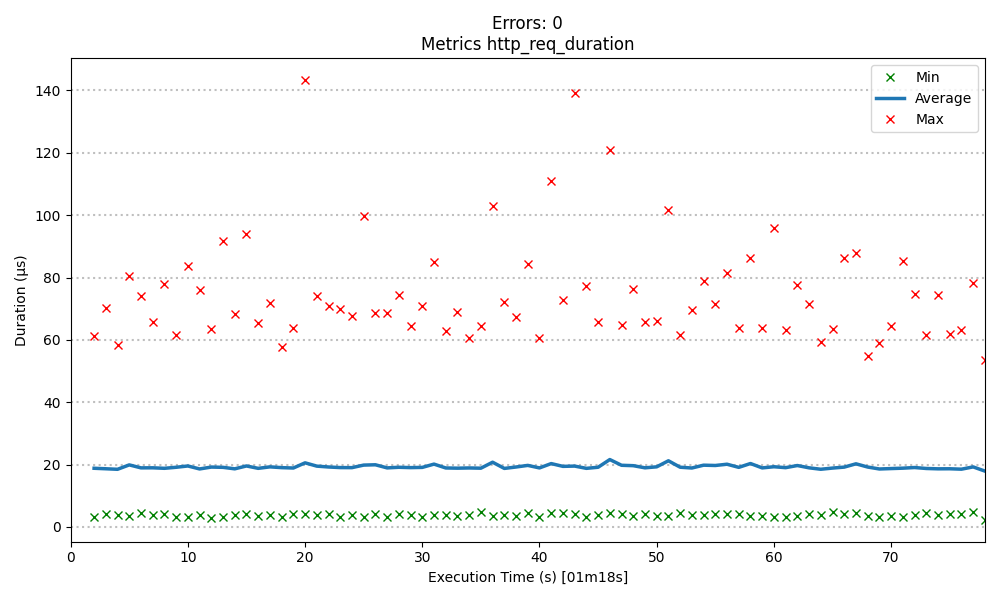
Total execution time: 1m18s
- Errors: 0
- Total execution time: 1m18s
Creating 60,000 records across 3,600 threads
The performance tests shown in the graphs measure the overall response time of custom resource creation in a Kubernetes environment. All tests were conducted under identical conditions, with the only variable being the number of database instances used to store resource data. Each test utilized RDS instances from a well-known cloud provider, ensuring consistency in database performance and network characteristics.
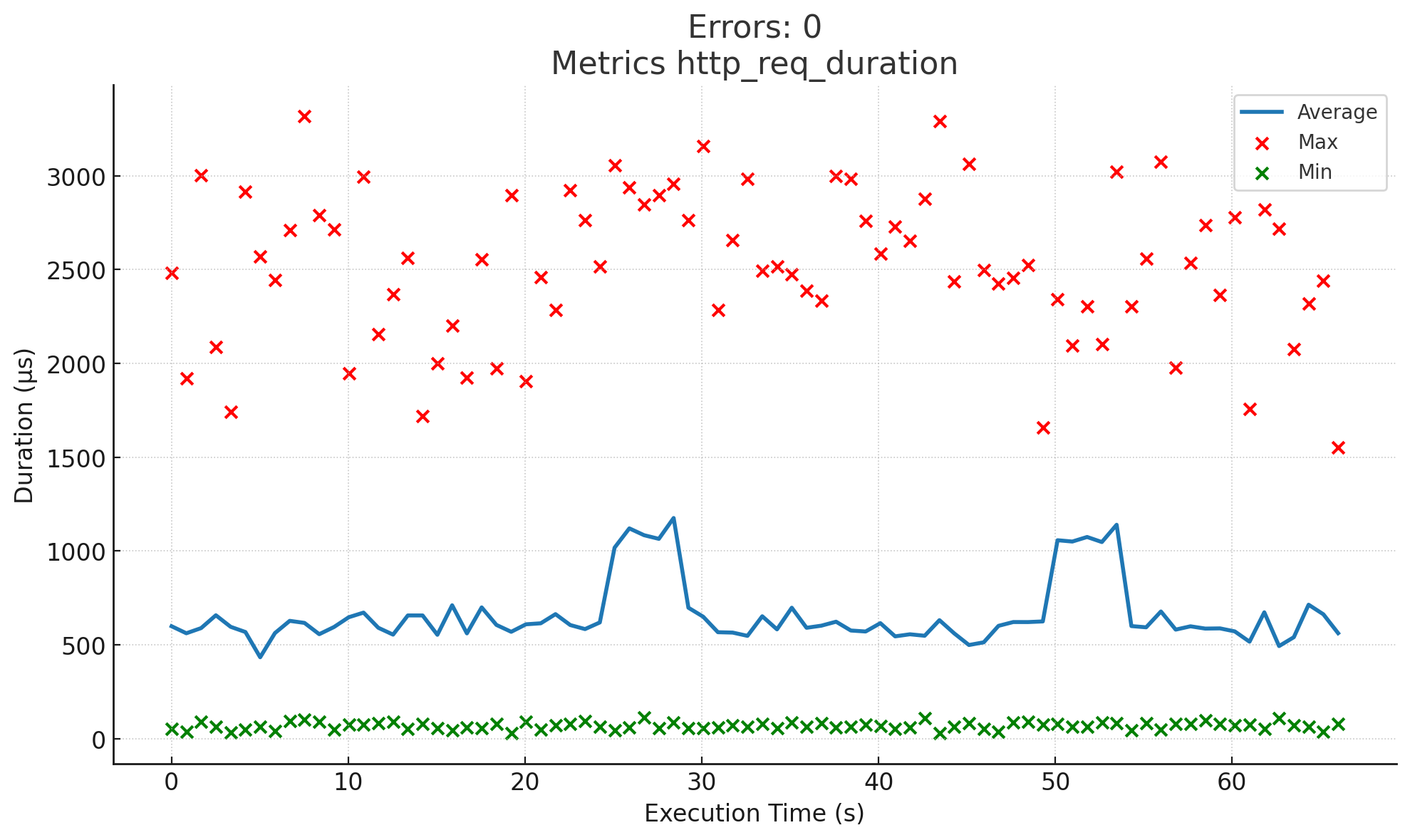
Total execution time: 1m6s
- Average response time: ~620 ms
- Maximum response time: ~3500 ms
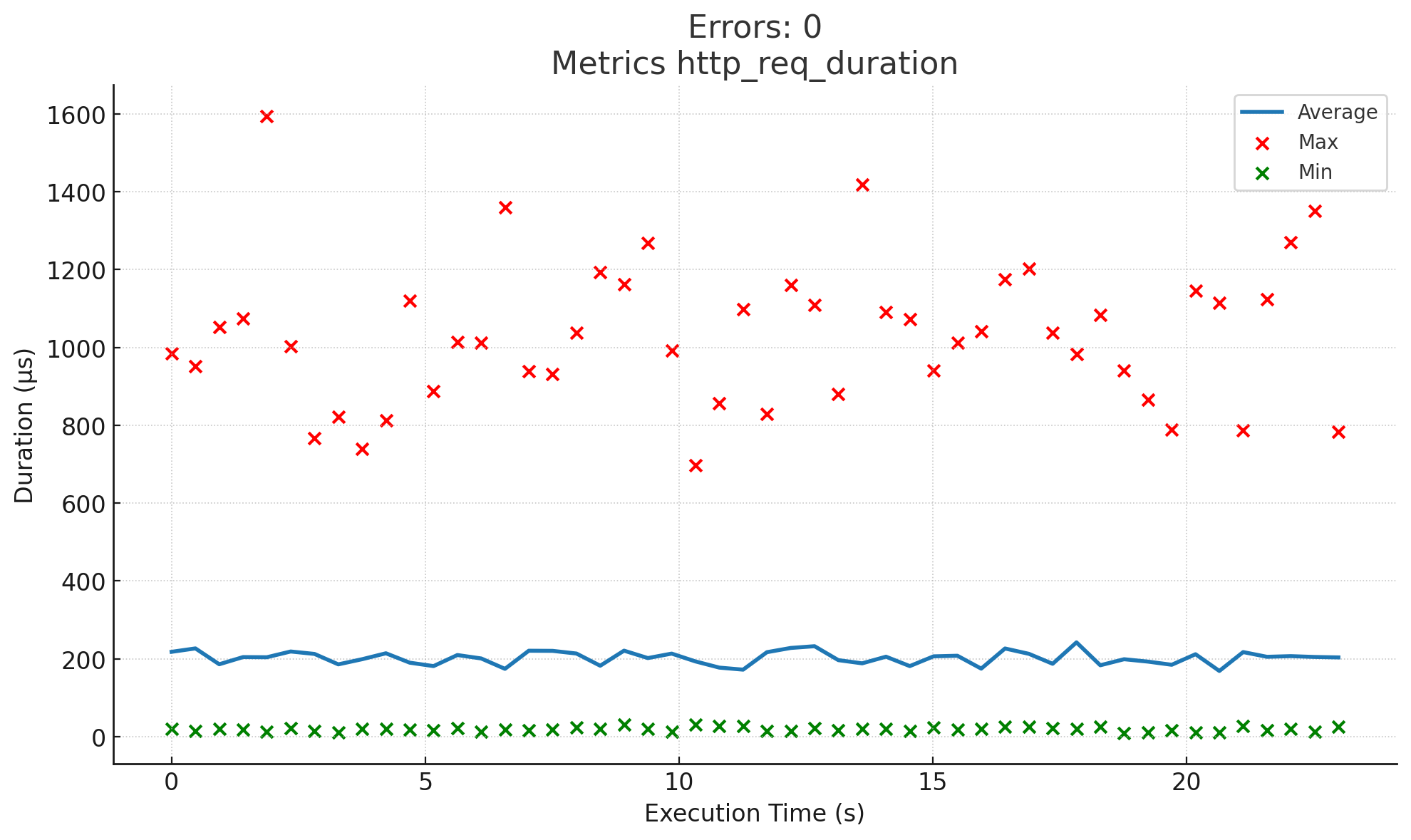
Total execution time: 23s
- Average response time: ~200 ms
- Maximum response time: ~1600 ms
Using 6 databases resulted in a 3× improvement in both throughput and latency, demonstrating strong scalability and reduced per-request overhead.
When using a single database, average response times were around 3× higher, with frequent latency spikes pushing maximum durations beyond 3500 ms. The overall execution took over 1 minute, and the system showed signs of bottlenecks and load accumulation.
In contrast, the 6-database setup showed a much smoother performance profile: average latencies dropped by a factor of 3, and peak response times were consistently lower, rarely exceeding 1600 ms. The total execution time dropped to 23 seconds, showing a near 3× improvement in both throughput.
The single-database setup also produced a ~3.9% error rate, while the 6-database HariKube configuration completed the test with zero errors near 3.5x faster, highlighting its superior reliability under load. The HariKube setup utilization was still low, but these were the numbers where the single database setup didn’t halt and catch 🔥.
📈 Still not impressed?
If a 200 ms average response time and 0 errors on 3,600 threads are still not enough for your specific use case, it’s time to go deeper. HariKube doesn’t just scale out; it allows you to optimize every individual “cell” in your data matrix to reach the physical limits of your hardware.
Here is how to push the performance ceiling even higher:
- Database Partitioning (Inside the Shard): Before adding more servers, optimize the one you have. HariKube is designed to work perfectly with native SQL partitioning. Create your schema and partitions manually. When HariKube pushes a query down to the DB, the SQL engine only scans the relevant partition. You get the speed of a sharded system within the simplicity of a single database connection.
- Upgrading to a Distributed Database (The “Drop-In” Scale): The most powerful way to scale the database is to replace a standalone MySQL/Postgres instance with a Distributed SQL Engine like TiDB or CockroachDB. To HariKube, TiDB looks like a single MySQL database. You provide one connection string. Behind that single connection, TiDB distributes your data across dozens of nodes.
- Introducing a Smart Load Balancer (Read/Write Splitting): To maximize throughput, you can place a State-Aware Proxy (like ProxySQL, MaxScale, Pgpool-II, or Pgcat) between HariKube and your database cluster. The Load Balancer identifies “Write” operations and routes them to the Database Leader/Primary. The Load Balancer identifies “Read” operations (GET, LIST) and distributes them across multiple Read Replicas. This offloads heavy “Watch” and “List” traffic from your primary database, ensuring that write operations remain lightning-fast and uncontended.
<– Developer Experience | Consistency –>
Read the Technical Whitepaper!
Beyond the Benchmarks: If 50% of your engineering effort is currently spent on platform integration rather than business logic, your infrastructure is a bottleneck. In our technical whitepaper, we share the research behind the Unified Service Model and demonstrate how HariKube eliminates the integration overhead that stalls enterprise growth.