Streamlined Cloud-Native Development
HariKube simplifies the developer workflow by abstracting infrastructure complexity. Focus purely on data structures and business logic while the platform handles data routing and storage.
TL;DR
Developers continue using stock Kubernetes APIs and workflows-HariKube operates transparently in the background and is only needed in the production environment. There’s no need to install or configure anything locally, keeping development environments lightweight and familiar.
HariKube seamlessly extends Kubernetes without disrupting native functionality-supporting RBAC, events, admission webhooks, and other core features out of the box. This ensures full compatibility with existing tooling and policies while enhancing the platform’s data capabilities behind the scenes.
HariKube preserves standard Kubernetes APIs and resource definitions, ensuring that applications behave identically across development, staging, and production. Since it operates transparently at the infrastructure level, no code changes or environment-specific logic are required.
By design, it remains vendor lock-free, ensuring you maintain complete sovereignty over your stack and can migrate across providers with ease. Furthermore, it streamlines the engineering workflow by requiring no 3rd-party libraries for development, allowing for a cleaner and more secure codebase.
Kubernetes has become the backbone of modern cloud-native development, offering a consistent and declarative way to manage infrastructure and application lifecycles. But as platforms evolve and microservices scale, infrastructure complexity often seeps into the developer workflow-slowing teams down and introducing friction.
While Kubernetes has enabled a powerful cloud-native development workflow, it remains fundamentally limited when it comes to handling data-intensive applications. This is because the underlying data store-ETCD-is optimized for configuration and state management, not high-throughput or large-scale operational data. As a result, cloud-native workflows are often confined to infrastructure automation, while application-level data handling must rely on external systems, breaking the end-to-end cloud-native paradigm.
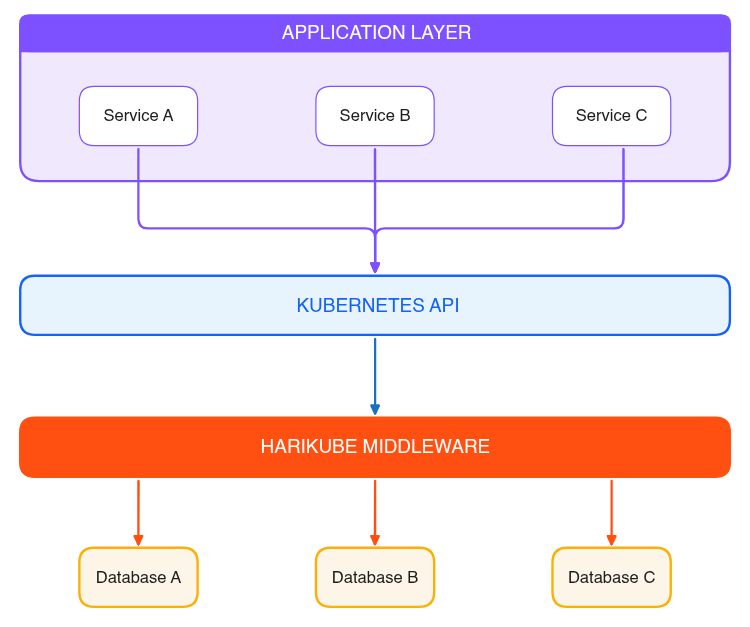
HariKube addresses this by decoupling infrastructure concerns from application development. It operates transparently within your Kubernetes cluster, letting developers work entirely within standard Kubernetes APIs while it routes and stores custom resource data in multiple databases behind the scenes.
Legacy vs. Unified Service Model
The Container Boundary
- Applications are silos on top of Kubernetes
- Bring Your Own Foundations
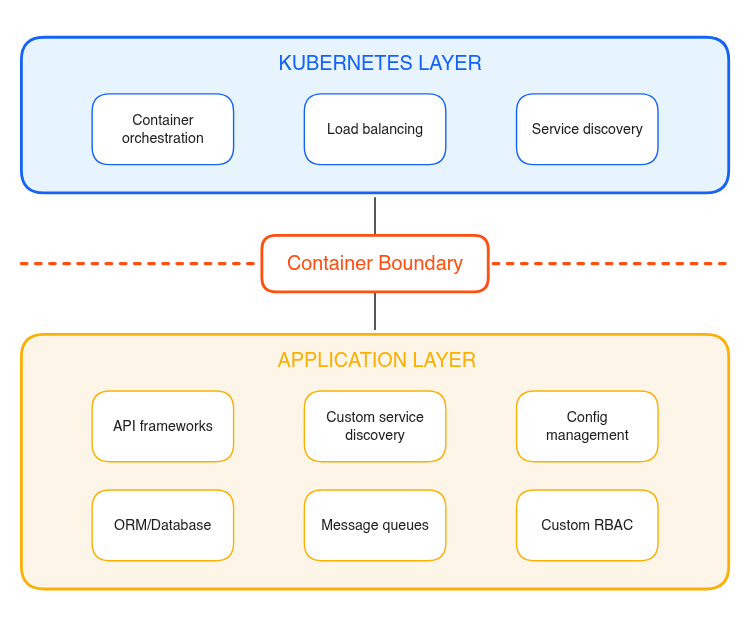
First Class Citizens
- Applications are part of Kubernetes
- Rely on Cloud-Native Foundations
Research consistently demonstrates that software engineers spend approximately 50% of their time on “glue code” and infrastructure integration rather than core business logic. Forget replication of boilerplate in each project, rely on Kubernetes built-in features instead.
Why It Matters
No local setup needed – Developers don’t need to run heavy database instances or mock ETCD clusters locally. Since HariKube is designed for production environments and integrates with stock Kubernetes APIs, development can remain fast, lightweight, and focused.
Cloud-native by default – With support for built-in Kubernetes features like RBAC, admission webhooks, and eventing, HariKube fits naturally into your existing toolchain-whether you’re using Helm, ArgoCD, or GitOps workflows.
Environment parity – Applications behave consistently across environments because there’s no custom runtime logic or external SDK to introduce variability. If it works in dev, it works in prod.
Built for simplicity – With fully documented APIs and plug-and-play integration, developers can rely on existing Kubernetes knowledge without the need to learn or manage another system.
Transforms Kubernetes into a true Platform-as-a-Service (PaaS) – HariKube abstracts data infrastructure complexity, allowing developer teams to focus solely on business logic. This streamlined workflow not only accelerates development but also reduces operational overhead and infrastructurerelated development costs.
Unifying different service designs - For years, Kubernetes has been the foundation of modern cloud infrastructure. But while it excels at scheduling, scaling, and managing workloads, its application development experience has been fragmented.
HariKube empowers platform teams to handle scale, compliance, and infrastructure complexity-while developers stay focused on writing and deploying great software.
- Serverless functions live in Knative or OpenFaaS.
- Operators are built with Kubebuilder or Kopf for infrastructure related developments.
- REST APIs are bolted on via Ingress and separate application stacks.
HariKube changes this. By replacing ETCD with a database-agnostic backend topology and connecting Kubernetes watches to serverless runtimes, reconciliation loops, and custom APIs. It turns Kubernetes into a true Cloud-Native Platform-as-a-Service.
Serverless - Nanoservice Layer
With a lightweight watch connector, every Custom Resource Definition (CRD) or core resource change can trigger a function running on OpenFaaS or Knative. The function layer provides event-driven business logic without requiring operators, custom APIs, or external event buses.
- Developers only need a CRD and a function image.
- Kubernetes acts as the event source.
- The function focuses on logic, the platform handles everything else.
Function languages: Go, Python, Node.js/TypeScript, Java, C#/.NET, Ruby, PHP, Rust.
In practice, any language that runs in a container and speaks HTTP works.
Operators - Microservice Layer
Operators remain the best way to handle stateful, long-lived, or complex business logic. With HariKube’s data fabric, operators behave like regular microservices without being bottlenecked by ETCD.
- Developers only need a CRD and an operator image.
- Kubernetes acts as the event source and API.
- The operator focuses on logic, the platform handles everything else.
Operator languages: Go, Python, Java, Node.js/TypeScript, Rust, C#/.NET.
⚠️ Limitations
While HariKube improves performance over single-ETCD setups, it inherits some Kubernetes design tradeoffs.
| Limitation | Description |
|---|---|
| Eventual Consistency | Updates may not be immediately visible across the system |
| Non-Transactional | No support for ACID transactions |
| Relational Logic | Complex joins or relations between data entities are not supported |
| Limited Data Filtering | No advanced query engine included within Kubernetes |
| Limited number of CRDs | Kubernetes Discovery API reaches it’s limit proximately around at 500 |
💡 Don’t worry, the Kubernetes API aggregation layer can help overcome the limitations of the core API server by allowing you to extend the API with custom APIs that are served by a separate backend, or extension API server. This setup enables you to implement specific logic and capabilities that aren’t available in the core API.
Kubernetes Aggregation API Layer - Traditional REST API Layer
Some use cases don’t fit into serverless or operator patterns - for example, classic REST APIs, querying, or external integrations. Here, Kubernetes’ Aggregation API layer lets you embed a custom API server directly into the Kubernetes control plane.
- Developers can deliver hybrid or full autonome services.
- Kubernetes acts as the API.
Typical REST/API languages: Go, Python, Node.js/TypeScript, Java, C#/.NET, Rust, Ruby, PHP.
In practice, any language that runs in a container and speaks HTTP works.
By unifying Serverless Functions, Operators, and Custom REST APIs into a single platform powered by the HariKube dynamic data layer, you overcome ETCD limits and transform Kubernetes into a full, scalable, and language-agnostic Hybrid PaaS.
Performance –>
Read the Technical Whitepaper!
Beyond the Benchmarks: If 50% of your engineering effort is currently spent on platform integration rather than business logic, your infrastructure is a bottleneck. In our technical whitepaper, we share the research behind the Unified Service Model and demonstrate how HariKube eliminates the integration overhead that stalls enterprise growth.