HariKube determines data locality using the object key structure and applies routing based on configurable policies,
such as matching by resource type, namespace, key prefix, or custom resource definition.
Routing configurations are evaluated in order from top to bottom, and the first matching rule determines the data’s target database. Once a match is found, subsequent rules are ignored for that resource.
Routing policies must be carefully designed, as adding or changing a policy for resource types that already have stored data can result in the existing records becoming inaccessible. HariKube does not migrate previously stored resources to the new target automatically, so any change in routing may lead to apparent data loss unless migration handled manually.
During runtime the middleware monitors configuration changes and applies new configuration, but only adding new configuration to the bottom is supported.
Names and endpoints must be unique in the configuration. If you have to change endpoint, first ensure all data exists on the new endpoint, and then restart the middleware. If you have to change name, restart the middleware and all services - including Kubernetes - which depends on historical data.
Update your endpoints, because the example uses Docker bridge IP!
ETCD with regular expression routing:
Routes Kubernetes RBAC resources to an ETCD store.
MySQL endpoint with namespace matching:
All objects in the kube-system namespace are routed to a MySQL backend.
If you want only a selected list of resources, you can configure them via kinds field. For custom resources you have to create a separate policy, because both given types and custom resources are not supported in the same time.
PostgreSQL endpoint with prefix matching:
All pods resources - except pods in kube-system namespace - are routed to a PostgreSQL backend.
SQLite endpoint for specific custom resources:
Routes all resources of type shirts in the group stable.example.com to a lightweight embedded SQLite database.
Rest of the objects are stored in the default database.
You can deploy multiple instances of the middleware, where each instance can be configured to delegate to another middleware as its backend. This enables the construction of a multi-layered, hierarchical topology, where data access requests can propagate through multiple layers of the middleware.
Initialize your primary middleware instance to act as the entry point for Kubernetes by launching it with the following configuration. This instance will serve as the top-level interface for Kubernetes API server requests, abstracting the underlying data storage layer while maintaining full compatibility with the etcd API.
ETCD endpoint with namespace matching:
All objects in the kube-system namespace are routed to a ETCD backend.
Rest of the objects are stored in the default database.
As shown, this middleware connects to a backing etcd server to store and retrieve objects within the kube-system namespace. However, instead of connecting directly to etcd, you can deploy another middleware that listens on kube-system.etcd.server:2379. This allows you to insert an additional routing layer between Kubernetes and the storage backend - enabling advanced behaviors, all while preserving the etcd-compatible API surface.
Update your endpoints, because the example uses Docker bridge IP!
ETCD endpoint with prefix matching:
All pods resources are routed to an ETCD store.
MySQL endpoint with prefix matching:
All secrets resources are routed to a MySQL backend.
PostgreSQL endpoint with prefix matching:
All configmaps resources are routed to a PostgreSQL backend.
SQLite endpoint with prefix matching:
All deployments resources are routed to a SQLite backend.
Rest of the objects are stored in the default database.
📘 Metadata Store Configuration
HariKube includes an internal metadata store that maintains mapping information about the underlying databases. It keeps track of which database is responsible for each data segment, ensuring consistency and fast lookups without querying every backend directly. The metadata store is central to HariKube’s ability to provide dynamic data placement, multi-database support, and high-performance routing across flat or hierarchical topologies. To configure metadata store you have to set environment variable(s) for the middleware. Default Metadata store is bbolt.
REVISION_MAPPER_CACHE_CAPACITY: Capacity of the in-memory cache. Default 10000
REVISION_MAPPER_FAILED_DIR: Directory path for storing non persistent revision maps, Default ./db/failed_mapper_revisions
The BBolt Mapper provides a lightweight, embedded solution for storing revision metadata with minimal setup and no external dependencies. Under the hood it leverages BBolt’s memory‑mapped, ACID‑compliant key/value store, while keeping an in‑memory cache of the latest revision data and batching writes to the BBolt’s file asynchronously. This means the mapper always reflects the current logical state in your application, even if the on‑disk BBolt’s file may briefly lag behind during high‑throughput writes.
REVISION_MAPPER=bbolt: Type of metdata store - Optional
REVISION_MAPPER_BBOLT_O2G_PATHS: Comma separated list of paths to the original-to-generated revision database directories. Default ./db
REVISION_MAPPER_BBOLT_G2O_PATHS: Comma separated list of paths to the generated-to-original revision database directories. Default ./db
REVISION_MAPPER_BBOLT_LEASE_PATH: Path to the lease database directory. Default ./db
REVISION_MAPPER_BBOLT_SYNC_PERIOD: Database sync to filesystem period. Default: 0s (instant)
REVISION_MAPPER_BBOLT_BATCH_SIZE: Size of batch write operation. Default 1
REVISION_MAPPER_BBOLT_WRITE_QUEUE: Buffer size of write queue. Default 1
Changing of database directories doesn’t supported at the moment.
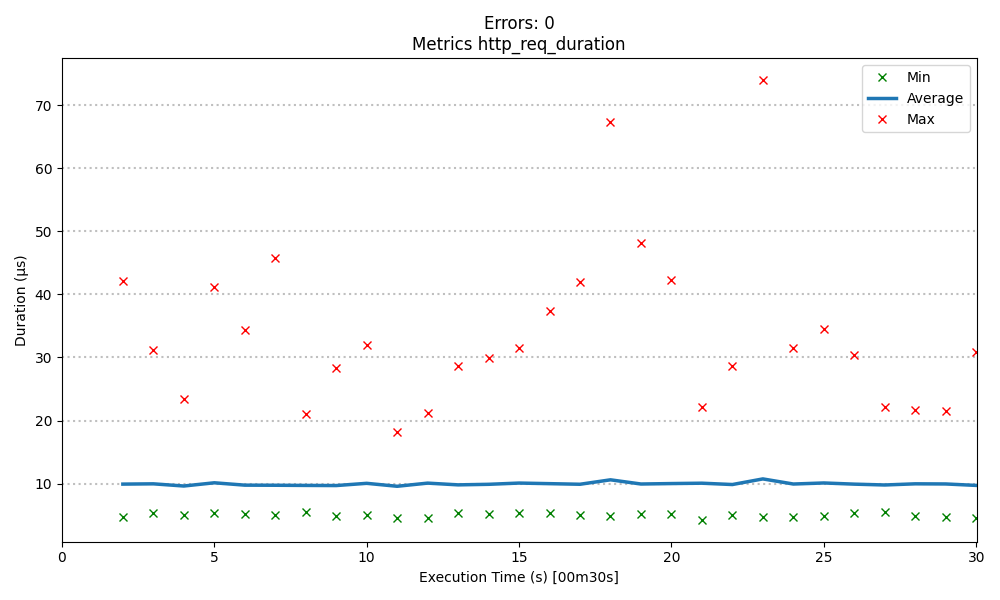
5000 records creation on 60 threads
Total execution time: 30s
Average response time: ~10 ms
Maximum response time: ~75 ms
The SQLite Mapper provides a lightweight, embedded solution for storing revision metadata with minimal setup and no external dependencies. The SQLite Mapper maintains an in-memory cache of the latest revision data and writes to the SQLite database asynchronously. This means the mapper is always aware of the current logical state, but the on-disk database may temporarily lag behind.
REVISION_MAPPER=sqlite: Type of metdata store
REVISION_MAPPER_SQLITE_O2G_PATHS: Comma separated list of paths to the original-to-generated revision database directories. Default ./db
REVISION_MAPPER_SQLITE_G2O_PATHS: Comma separated list of paths to the generated-to-original revision database directories. Default ./db
REVISION_MAPPER_SQLITE_LEASE_PATH: Path to the lease database directory. Default ./db
REVISION_MAPPER_SQLITE_SYNCHRONOUS: Write mode of the database [OFF, NORMAL]. Default OFF
REVISION_MAPPER_SQLITE_WRITE_QUEUE: Buffer size of write queue. Default 1
REVISION_MAPPER_SQLITE_MAX_CONNECTIONS: Number of max connections to the database. Default 1
Changing of database directories doesn’t supported at the moment.
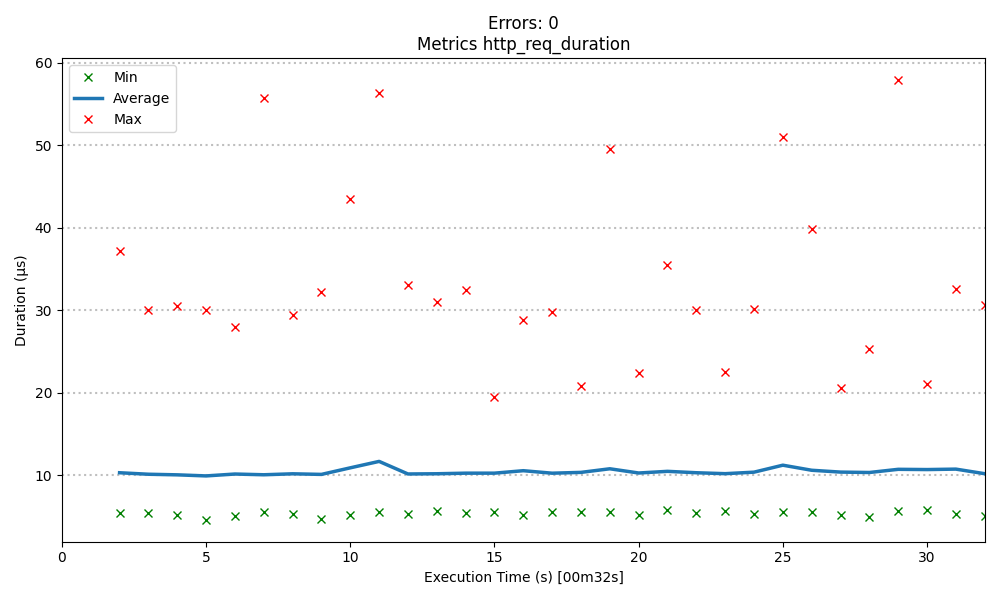
5000 records creation on 60 threads
Total execution time: 32s
Average response time: ~11 ms
Maximum response time: ~59 ms
🔌 Middleware Configuration
⚠️ A valid license is required to proceed - at least free Starter Edition. We invite you to explore our various licensing tiers on our Editions page.
The middleware is designed to operate seamlessly in both containerized and traditional environments. It can be executed within a Kubernetes cluster (e.g., as a Pod or Deployment) or deployed external to the cluster. All operational configuration files and parameters are standardized and require no modification based on the deployment location.
--listen-address: Listen address of service. Default: unix://kine.sock
--endpoint: Defines the default fallback database used to store any data not explicitly routed by the topology configuration
--ca-file: Path to the Certificate Authority (CA) file used to establish trust for the default database connection
--cert-file: Path to the client certificate file used to authenticate with the default database during TLS handshake
--key-file: Path to the private key file used in conjunction with the client certificate to authenticate the default database connection
--skip-verify: Controls whether the TLS client performs server certificate verification
--log-format: Log format to use. Options are ‘plain’ or ‘json’. Default ‘plain’
--metrics-bind-address: The address the metric endpoint binds to. Default :8080, set 0 to disable metrics serving
--server-cert-file: Path to the TLS certificate used by the middleware to secure incoming client connections
--server-key-file: Path to the private key used by the middleware to establish secure TLS communication with etcd-compatible clients
--datastore-max-idle-connections: Maximum number of idle connections retained by default datastore. If value = 0, the system default will be used. If value < 0, idle connections will not be reused
--datastore-max-open-connections: Maximum number of open connections used by default datastore. If value <= 0, then there is no limit
--datastore-connection-max-lifetime: Maximum amount of time a default database connection may be reused. If value <= 0, then there is no limit
--datastore-connection-max-idle-lifetime: Maximum amount of time a default database idle connection may be reused. If value <= 0, then there is no limit
--slow-sql-threshold: The duration which SQL executed longer than will be logged. Default 1s, set <= 0 to disable slow SQL log
--slow-sql-warning-threshold: The duration which SQL executed longer than will be logged at level warn. Default 5s
--metrics-enable-profiling: Enables Go performance profiling via net/http/pprof on the metrics bind address. Default is false
--watch-progress-notify-interval: Interval between periodic watch progress notifications. Default is 5s
--emulated-etcd-version: The emulated etcd version to return on a call to the status endpoint. Defaults to 3.5.13, in order to indicate support for watch progress notifications
--compact-interval: Interval between automatic compaction. Default is 5m
--compact-interval-jitter: Percentage of jitter to apply to interval durations. A value of 10 will apply a jitter of +/-10 percent to the interval duration. It cannot be negative, and must be less than 100. Default is 0
--compact-timeout: Timeout for automatic compaction. Default is 5s
--compact-min-retain: Minimum number of revisions to retain when compacting. Default is 1000
--compact-batch-size: Number of revisions to compact in a single batch. Default is 1000
--poll-batch-size: Number of revisions to poll in a single batch. Default is 500
--debug: Enable debug logging
Environment variables:
LICENSE_KEY_FILE: File path for the license file
TOPOLOGY_CONFIG: File path for the topology configuration, which is continuously scanned for modifications, supported formats are:
file://<file-path>
http(s)://<file-url> - Polling interval is 1 minute
secret://<namespace>/<name> - Ensure this secret is stored at main database, and strongly suggested to add finalizer to prevent deletion. Files are consumed in name order
TOPOLOGY_CONFIG_TLS_DIR: Directory path for storing TLS files provided by topology secret, Default ./db/tls
LIST_MAX_ITEMS: Max items for list operations. Default 10000
ENABLE_TELEMETRY_PUSH: Enables pushing anonym usage telemetry to HariKube central monitoring site https://monitoring.harikube.info
CUSTOM_RESOURCE_DEFINITION_METADATA_FILE: Locatin to store Custom Resource Definition metadata. Defaut: ./db/crds.json
GARBAGE_COLLECTION__DIR: Directory path for storing garbage-collection logs of storage side GC, Default ./db/garbage-collector
GARBAGE_COLLECTION_EXIT_ON_ERROR: What to do when delete log write fails. Setting to false should result orphan resources. Default true
To continuously improve our software and deliver the best possible experience, we kindly ask you to enable telemetry. When enabled, your application will periodically send anonymized usage data to our central telemetry collector. This data helps us understand how the software is used in real-world scenarios and allows us to detect bugs, optimize performance, and prioritize new features.
We do not collect any sensitive or personally identifiable information. All collected data is strictly anonymized and used solely for diagnostic and analytical purposes. Examples include feature usage frequency, error events, and environment metadata like OS type or version.
Telemetry is entirely optional and enabled by ENABLE_TELEMETRY_PUSH environment variable. By enabling it, you contribute to a better and more stable product for everyone. To enable telemetry, please ensure your network allows egress traffic to https://monitoring.harikube.info.
Thank you for supporting the project!
📈 Database Configuration
The HariKube removes the “Single Connection” constraint, introducing native multi-database sharding. This allows you to orchestrate an unlimited fleet of independent databases through a single entry point. By using industry-standard layering, you can scale each individual database in your matrix to handle massive workloads.
Database Partitioning (Inside the Shard): Before adding more servers, optimize the one you have. HariKube is designed to work perfectly with native SQL partitioning. Create your schema and partitions manually. When HariKube pushes a query down to the DB, the SQL engine only scans the relevant partition. You get the speed of a sharded system within the simplicity of a single database connection.
Upgrading to a Distributed Database (The “Drop-In” Scale): The most powerful way to scale the database is to replace a standalone MySQL/Postgres instance with a Distributed SQL Engine like TiDB or CockroachDB. To HariKube, TiDB looks like a single MySQL database. You provide one connection string. Behind that single connection, TiDB distributes your data across dozens of nodes.
Introducing a Smart Load Balancer (Read/Write Splitting): To maximize throughput, you can place a State-Aware Proxy (like ProxySQL, MaxScale, Pgpool-II, or Pgcat) between HariKube and your database cluster. The Load Balancer identifies “Write” operations and routes them to the Database Leader/Primary. The Load Balancer identifies “Read” operations (GET, LIST) and distributes them across multiple Read Replicas. This offloads heavy “Watch” and “List” traffic from your primary database, ensuring that write operations remain lightning-fast and uncontended.
Installation Options
The recommended, most effective, and simple architectural approach for deploying services within a HariKube environment is by leveraging virtual clusters. This strategy uses tools like vCluster to create lightweight, isolated Kubernetes environments that operate inside a larger, physical host cluster.
This model provides clear separation between services and the underlying infrastructure orchestration, delivering significant operational and security benefits.
Works Seamlessly on Cloud and Bare-metal
Decoupled Infrastructure Management
Enhanced Multi-Tenancy and Isolation
Independent Scaling and Configuration
Fine-Grained Resource Synchronization between host and virtual clusters
Start by bringing your favorite Kubernetes deployment.
⚠️ A valid license is required to proceed - at least free Starter Edition. We invite you to explore our various licensing tiers on our Editions page.
Next step is authenticating your local registry client with the private registry at registry.harikube.info. This step is essential for pulling images from the registry.
Store your previously created topology config, or create configs on the fly with our automation tool. You can edit the secret any time, the middleware will apply the changes.
🔓 vCluster simplifies the operational workflow by automatically updating your local environment. For more details how to disable this behaviour, or how to get config by service account for example please wisit the official docs` Access and expose vCluster section.
KUBECONFIG Update: Upon successful creation or connection of the virtual cluster, vCluster automatically updates your local $KUBECONFIG file to include a new context pointing directly to the virtual cluster’s API server.
Ready for Use: This means you are immediately ready to interact with the new virtual cluster. You can verify connectivity and begin deployment using standard Kubernetes tools.
Service Access From Host
🔓 For service access from host, the vCluster setup keeps things simple: Create your ServiceAccount, generate a secret with the command below, and vCluster will sync the secret to the host cluster.
Now you can mount the secret to your workload to talk with the virtual cluster.
Kubernetes is compatible with HariKube by default. However, due to architectural constraints in ETCD-its underlying storage system-it is not optimized for handling very large datasets. To enable support for high-volume data workloads, modifications to specific Kubernetes components (such as the API server) are required and shipped.
🚀 Setup and start Kubernetes
Kubernetes Configuration
HariKube requires specific Kubernetes configuration to enable custom resource routing and external data store integration.
⚠️ A valid license is required to proceed - at least free Starter Edition. We invite you to explore our various licensing tiers on our Editions page.
Start by authenticating your local Docker client with the private registry at registry.harikube.info. This step is essential for pulling images from the registry.
For users requiring a completely isolated and dedicated Kubernetes cluster, HariKube supports the deployment of standalone Kubernetes environments.
To facilitate this, we provide pre-built multi architecture images that are optimized and ready for configuration via Kubeadm or any other orchestration tools.
exportKUBE_FASTBUILD=true# false for cross compilingexportKUBE_GIT_TREE_STATE=clean
exportKUBE_GIT_VERSION=v1.35.0
make WHAT=cmd/kube-apiserver
make WHAT=cmd/kube-controller-manager
Find the compiled binaries in _output/local/bin/linux/amd64 folder.
1
2
3
4
5
exportKUBE_FASTBUILD=true# false for cross compilingexportKUBE_GIT_TREE_STATE=clean
exportKUBE_GIT_VERSION=v1.35.0
./build/run.sh make WHAT=cmd/kube-apiserver
./build/run.sh make WHAT=cmd/kube-controller-manager
Find the compiled binaries in _output/dockerized/bin/linux/amd64 folder.
1
2
3
4
5
exportKUBE_FASTBUILD=true# false for cross compilingexportKUBE_GIT_TREE_STATE=clean
exportKUBE_GIT_VERSION=v1.35.0
exportKUBE_DOCKER_REGISTRY=<your-registry.example.com/kubernetes>
make release-images
Find the baked images at the local registry:
1
docker image ls | grep -E 'kube-apiserver|kube-controller-manager'| grep $KUBE_GIT_VERSION